KH Coder使用レポート

基本的な分析手順
- コーパスデータ(テキストファイル(*.txt)もしくはHTMLファイル)を開く
- 前処理を行う(茶筌で形態素解析する)
- 集計や検索をする
何ができるか
- データ抽出・検索機能
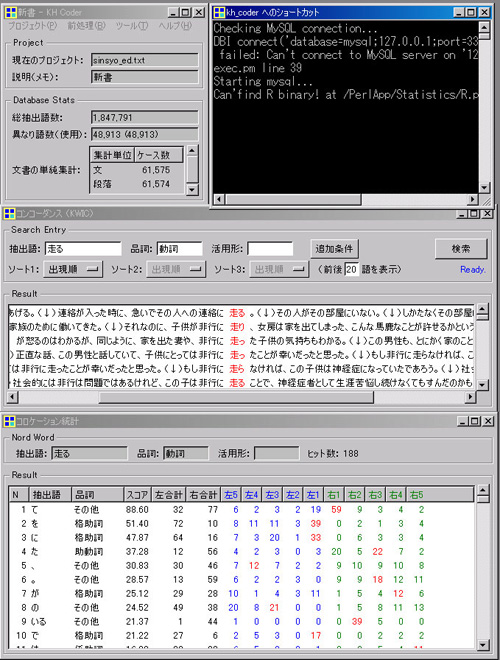
- 文字列による検索: コーパスに含まれている文字列の単純な検索.例えば,新潮文庫100冊に含まれている「バス」という語をKWIC形式で表示させ,保存することができる.
- 品詞による検索: コーパスに含まれている特定の品詞を検索.例えば,新潮文庫100冊に含まれている「名詞」をKWIC形式で表示させ,保存し,前後文脈の集計もできる.なお,品詞体系は基本的には茶筌の体系に依存する.中のConfigファイルを変更することで調査目的にあった品詞の定義ができるように設計されている.
- 文字列と品詞による検索:文字列と品詞を組み合わせて検索し,表示することができる.
- 語基による一括検索:動詞などの語基のみを入力し,検索することで,その派生形を一括で検索することができる.例えば,走る+動詞で検索するだけて,「走らない」,「走りたい」といった様々な語形のものが一括で拾える.
- 生起文脈を絞り込んで検索:生起文脈を限定し,検索することができる.例えば,ガ格の後ろに生じている「走る」の用例のみを検索するといったことができる.あるいは「走る」の後ろに名詞が生じている用法のみを検索することで,連体修飾表現のみを取り出すこともできる.
- データ集計機能
- 品詞別出現頻度数の調査: エクセルに連携されており,コーパス全体の品詞別の出現頻度数を出力させることができる.
- 記述統計の出現回数: コーパス全体の語彙の分布を調べることができる.異なり語数と延べ語数を調べることができ,コーパス全体の大きさを簡単に把握できる.あるいは一回のみ生起した語(ハパックス)の数がどれくらいで,生起頻度や標準偏差も調べられ,そのコーパスの特徴を理解することができる.
- コロケーション統計: 検索語の前後にどのような語彙がどれだけ使用されているかを調べることができる.
- これの他,特定の語彙のグループをコーディングし,それらを集計することができたり,文脈ベクトルを生成し,語彙と語彙の関係を(自己組織化マップなどで)可視化することもできるなど,様々な機能が搭載されている.
感想
- 非常に優れたデータ抽出機能を持っており,言語学的利用にも必要充分な機能を備えており優れたツールと言える.
- パッケージ内にはエクセルの便利なアドインも付いており,至れり尽くせり.また茶筌の解析エラーを補強する機能が付いているのも嬉しい.
最終更新:2009年05月09日 23:32
